深層学習の概略
- 大量の文字フォント画像によるCNN深層学習 最も小さい標準辞書で漢字/ひらがな/カタカナ/記号で15750、英数字で21240の異なる文字フォント画像でCNN系統のモデルによって学習。
- word2vecを文字に対して適用したchar2vecのCBOWモデルによる学習 word2vecは、単語を属性の多次元ベクトルに変換するためのニューラルネットである。
学習対象のデータは総計200GB。漢字/ひらがな/カタカナ/記号/英数字を合わせた対応文字種は、従来から1000文字種以上増えて5438文字種となっている。
| 開発プロセス | ||||
|---|---|---|---|---|
| 学習 | 74,000ファイル、200GBのフォントパターン+ラベルをオンメモリ処理不可能な巨大データ学習用のTFRecord形式に統合、変換。 TFRecord形式は、TensorFlow固有のファイルフォーマットである。メモリに乗り切らない巨大なデータや数万ファイルに分散格納された学習データを効率よく処理することができる。 TFRecord形式のファイル化した学習データをTensorFlow / Keras上のモデルで学習(560万パラメータ)。 |
モデル CNN MobileNet-I MobileNet-II ハイパーパラメータ 層数 各層のノード数 ミニバッチ 正規化 損失関数 活性化関数等 を切り替えつつパラメータ数が少なくて精度が高いものを選択。 |
モデルをPython / Numpy上で動作するように移植 移植は比較的簡単 途中経過を細かく出力する |
GPU必須 SSD必須 64bit動作 マルチスレッド不可 |
| 推論 | モデルをC++上で動作するように移植 移植は比較的難しい 途中経過を細かく出力して、Python / Numpy上の出力と比較して同じ動作をするようにデバッグ/調整)。 |
さらにチューニングして 省メモリ化 高速化 マルチスレッドによる並列処理対応 を行う。 |
深層学習対応OCRを従来型OCRライブラリから呼び出せるように組み込み | GPU不要 SSD不要 32bit/64bit動作 マルチスレッド可能 |
Python言語のコードを参考に推論部をC++へ移植した。
学習対象のデータは200GBと膨大で、当然メモリ中に全てを読み込むことはできない。学習データをTensorFlowのTFRecordというフォーマットのファイルに変換することで、学習時に200GBのデータに対して メモリに部分的に読み込みつつ、シャッフル/ミニバッチ処理を並列で繰り返し学習処理を適用している。
また、学習にはGPUが必須(学習速度が10倍高速化)となる。学習データも200GBのファイル(TFRecordフォーマット)のランダムアクセスが必要となるためSSD上にデータを置くことも必須となる。
SSDだと、hddと比べて、データ読み込み速度が40倍以上速くなる。
GPU無し、USB2.0接続のhddなどで学習するとかなり悲惨なこととなり、モデルを切り替えたり、ハイパーパラメータをチューニングしたりする作業が困難を極めることとなる。
Kerasでは、CNN/MobileNet I/MobileNet IIなどのモデルを試し、層数/ノード数/活性化関数/損失関数といったハイパーパラメータの最適な組み合わせをリサーチした。
|
MobileNetは、I~IIIまでのモデルがあり、モバイル機器での実行、GPUやメモリ量に期待できない組み込み用途での実行を目的としたモデルである。 メモリの負荷、計算量が下がる代わりに、多少の精度を犠牲にする。今回はIとIIを試した。 言語処理で使っているAI推論は、自然言語AI処理の基礎になる入り口の部分である。 自然言語処理分野でも省メモリの軽量モデルが存在している。BERTに対するMobile BERT、画像認識にTransformerを使ったViTに対するMobile ViTのように、 精度を犠牲にして少メモリ/ローカルマシンで実行するようにカスタマイズしたモデルはいろいろと提案されている。中にはモデルを軽量化しすぎて精度的に実用レベルに達しないケースも多い。 |
C++に移植することで、Pythonベースでは困難な32bit動作/マルチスレッド動作が可能になった。もちろん64bit版環境下でより高速に動作するライブラリもある。
速度は、GPUの無い環境での認識のためシングルスレッドでは100~200文字/秒となる。
高速な従来型エンジンとのハイブリッド動作によりシングルスレッドで650文字/秒を実現。ハイブリッド動作では高品質な文書画像ではより速くなる。
ただしマルチスレッド動作が可能でCPUのマルチコアを使った並列処理によって1200~7000文字以上/秒(コア数に依存)という、GPU利用をはるかに超える高速処理が可能となっている。
機械翻訳や要約で使われるseq2seqや、ロボット会話や論文/判例解析などに利用されているtransformer/BERT/GTPという巨大な言語モデルの基礎になるのが単語を多次元ベクトル化するword2vecである。
word2vecでは単語が処理単位となるが、今回利用したchar2vec(正式名称として"char2vec"というものが存在するかは不明)は文字が処理単位となる。
特に日本語の漢字は英語のアルファベットとは異なり意味的な要素を多く持っている。
char2vecもある程度効果を発揮することが期待できる
word2vecのポピュラーな利用方法である単語(文字)の分散表現を求めて類似度を求めるという機能は使っていない。
前後の文字から中央の文字を推測するという機能だけを使っている。
また、char2vecによるニューラルネットワークによる推論と、ngramベースによる統計的推論の精度は実験ベースではあまり変わらない。そこで、ngramベースの従来型の言語処理を、char2vecによる推論に 切り替えるのでは無く、ngram統計による推論に加えてchar2vecという二重の推論を行うことで新しいOCRライブラリの言語処理とすることにしている。
| 従来型OCRと深層学習OCRの言語処理 | |
|---|---|
| 従来型OCR | 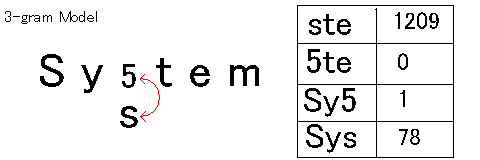 |
| 3-gramモデルでは日本語のコーパスから連続する3文字の頻度を全てカウントしてデータベース化したものを使う。 上の例では正解の"System"のはずが"Sy5tem"と誤認識しているが、3文字目の第2候補には"s"が入っている。 "ste"の頻度1209は"5te"の頻度0よりも高く、"Sys"の頻度78は"Sy5"の頻度1よりも高いという情報をデータベースから取得することができる。 その情報を使うことで、第1候補の"5"は下位に移動して、第2候補の"s"の方を採用する。 | |
| 深層学習OCR | 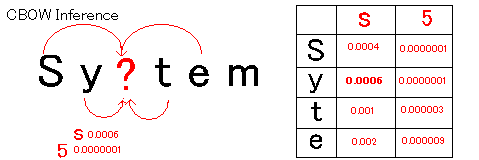 |
| word2vecには、周辺の文字から中央の文字を推測するCBOWモデルと、逆に中央の文字から周辺の文字を推測するskip-gramモデルがある。 今回は前後2文字から推測するCBOWモデルを使っている。1文字前の"y"との関連だけ見ると、"5"である確率0.0000001よりも"s"である確率0.006の方が高い。 そこで候補を入れ替えることで"System"という正解に変更することができる。 | |