Common Effects with Other Deep Learning OCR
- Improved accuracy with deep learning support Improved accuracy through deep learning with over 15,000 font patterns and over 200GB (grayscale) training data. Enhanced accuracy with 5.6 million parameters.
(Conventional OCR uses statistically compressed pattern data of 600 font patterns and 800MB (monochrome))
Improved accuracy with grayscale and color support
(Conventional OCR supports only monochrome 2-value. It is binarized before library invocation)
What makes our deep learning support different from others
- High-speed recognition 650 characters per second on a Core i7-9750H 2.59GHz laptop. 1300 characters per second on a Core i9-7900X 3.3GHz desktop PC.
- Training processing for patterns that cannot be recognized is instant (within 1 ms). Results are immediately reflected in recognition results.
- Past assets such as user pattern dictionaries and user language dictionaries registered with conventional OCR libraries can be used as is
Multi-threading enables recognition speeds of approximately 3 to 4 times faster (over 2000 characters per second) on a laptop. Recognition speeds of approximately 13,000 characters per second (about 10 times faster) are possible on a desktop PC.
Simultaneous execution of recognition processes for multiple processes at the same time. Simultaneous processing of 4 to 8 processes on a laptop and 12 to 16 processes on a desktop PC without any decrease in speed.
Comparison: Recognition speeds with Python + TensorFlow with GPU
With python + TensorFlow (GPU enabled), the speed is 350 characters per second (on a laptop with Intel Core i7-9750H 2.59GHz and NVIDIA Geforce RTX 2060 / 32-bit execution). This includes paragraph extraction and line extraction processing.
| Condition python + TensorFlow (GPU enabled) | Speed |
|---|---|
| Inference processing during training Character image of 48 pixels × 48 pixels from the beginning Mini batch size 1024 | 7000 characters per second Multi-threading and multi-processing not available |
| Case where inference processing is called one character at a time Character image of 48 pixels × 48 pixels from the beginning Mini batch size 1 | 700 characters per second Multi-threading and multi-processing not available |
| Case where inference processing is called one character at a time (almost the same conditions as our library (without language processing)) Paragraph extraction / line extraction / character extraction / normalization to 48 × 48 pixels Mini batch size 1 | 350 characters per second Multi-threading and multi-processing not available |
| Case where inference processing is called one line (average 17 characters) at a time (without language processing) Paragraph extraction / line extraction / character extraction / normalization to 48 × 48 pixels Mini batch size 17 | 1200 characters per second Multi-threading and multi-processing not available |
The speed of our deep learning compatible OCR is as follows
| Condition C++ version deep learning compatible OCR library | Speed |
|---|---|
| Using the training results with python + TensorFlow (GPU enabled) | |
|
Operation of our library (one character at a time) Paragraph extraction / line extraction / character extraction / normalization to 48 × 48 pixels / language processing included |
Speed of single-threaded deep learning OCR is 650 characters per second (32-bit version on a laptop) / 1300 characters per second or more on desktop conditions & 64-bit version Speed can be accelerated up to 2000 characters to 10,000 characters per second with multi-threading Speed can be accelerated by 1.8 times with 2 threads, achieving a recognition speed of 1200 characters per second (laptop conditions), surpassing the recognition speed of python + TensorFlow (GPU enabled) by 3 times Speed can be accelerated by 3.5 times with 4 threads. Speed of deep learning OCR reaching 2200 characters per second (laptop conditions), surpassing the recognition speed of python + TensorFlow (GPU enabled) by more than 6 times (It seems that the reason why speed does not increase by 4 times with 4 threads is that threads that cannot utilize CPU cache are generated) Multi-processing possible. Simultaneous execution of 4 to (laptop) and 8 to (desktop PC) processes without any decrease in speed |
Approach: Compatibility with conventional OCR libraries
- Support for existing library users even in the 32bit environment The library is provided in both 32-bit and 64-bit versions. A lightweight deep learning model is used to ensure compatibility with 32-bit applications, which are commonly used by existing users. In the 64-bit version, even faster operation has been confirmed.
- Operation in environments without GPU necessary for existing library users/Need for multi-threaded operation The inference portion is written in C++. The option of parallelization through multi-threaded operation without using a GPU has been chosen. As a result, even in a single-threaded operation, it is faster than Python/TensorFlow/Keras+GPU.
- Improved accuracy through the use of deep learning Unlike the conventional OCR library that targeted binary images, by recognizing grayscale/color document images, the influence of blurring and distortion due to binarization is eliminated.
- Inference-based language processing (scheduled for release in the first quarter of 2023) The conventional OCR library utilized statistical language processing based on 3-gram, using the frequency information of connecting two subsequent characters. In contrast, the inference-based AI language processing uses a total of 6 characters, with 3 characters before and after, to make predictions.
- Inheritance of assets from conventional OCR libraries Prior recognition based on registered patterns is possible. Additionally, specialized terminology dictionaries for language processing (in the old format) can be used as is. By using specialized terminology dictionaries for drawing terms, annotations (prefecture, city, town, and village names), and personal names, more accurate language processing is possible.
Note that Python (using numpy: GPU enabled) version of deep learning OCR has also been tested, but it is not publicly released and is only used for performance/functionality comparisons.
| Operating Environment | ||
|---|---|---|
| Conventional OCR | Deep Learning OCR | Python version of Deep Learning OCR |
| 32-bit/64-bit | 32-bit/64-bit | 64-bit |
| Parallel operation possible with multithreading | Parallel operation possible with multithreading | Cannot perform multithreaded operation |
| GPU not required | GPU not required | GPU required (very slow without it) |
| C++ implementation | C++ implementation | Python/TensorFlow/Keras implementation |
The number of recognized characters has been increased from 4,000 to 5,438. The font pattern per character has also increased by more than 100 times from the monochrome binary image pattern of 300 in the conventional OCR to more than 35,000 grayscale images (over 200 GB).
The size of the font image used for training has increased from about 150MB in the conventional OCR to about 200GB (due to the increase in the number of characters, the increase in the number of font patterns, and the grayscale conversion).
In addition to the increase in data volume, the use of deep learning has also improved the accuracy of the algorithm itself.

Increased the number of recognized characters by over 1,400, increased font patterns by 2 digits, and grayscale conversion.
The 3-gram dictionary is created by counting all combinations of 3 consecutive characters from a Japanese corpus of 300MB (including a Japanese corpus of around 30MB, a personal name dictionary, a national corporate dictionary using the My Number database, a Japanese address database using the database of JP, the complete list of entries in Kojien dictionary, all texts from 100 volumes of Shincho Bunko, and the complete list of entries in Japanese Wikipedia, among others).
The inference-based AI dictionary modifies the neural network that predicts the central word from the surrounding words to predict the central character from the surrounding characters in Japanese, rather than words.
The inference dictionary used for prediction is trained on a corpus of a total of 3.7GB, which includes the corpus of conventional OCR and the main text of Japanese Wikipedia, which exceeds 3GB in size.
The accuracy of the inference-based method is high, and with a corpus that is more than 10 times larger, it achieves even higher accuracy in language processing.
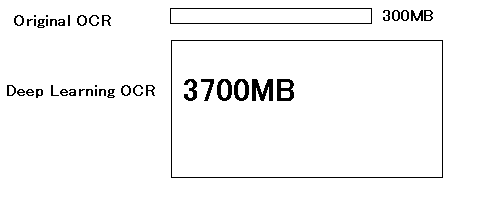
The original corpus of the language dictionary is over 12 times larger. From count-based to AI inference-based.
| Function and Performance Comparison | ||||
|---|---|---|---|---|
| Conventional OCR | Deep Learning OCR (Without GPU, 5.6 million parameters) | Deep Learning OCR (With GPU, 5.6 million parameters) | ||
| Overview | OCR based on a traditional method released in 2000, without GPU support (in C/C++) | A mode that inherits assets from conventional OCR while also enjoying the benefits of deep learning support. (in C/C++, without GPU support) | A speed comparison dedicated mode, using Python+TensorFlow+Keras with GPU support | |
| Recognition Accuracy | High-quality: 99.0%~ Low-quality: 95.0%~ |
High-quality: 99.5%~ (Half the misrecognition rate of conventional OCR) Low-quality: 98%~ (Significant effect at low quality) Further reduction in misrecognition through AI language processing Adjustment of accuracy priority or speed priority is possible |
High-quality: 99.5%~ (Half the misrecognition rate of conventional OCR) Low-quality: 98%~ (Significant effect at low quality) |
|
| Recognition Speed (including paragraph extraction, line extraction, and character extraction) | 1300 characters/second Speed can be increased by 2 to 10 times with multi-threading (depending on the number of CPU cores) Approximately 4 times faster than python+TensorFlow with GPU utilization in single-threading |
650 characters/second Speed can be increased by 2 to 10 times with multi-threading (depending on the number of CPU cores) Simultaneous multi-execution possible Simultaneous multi-execution of multi-threaded processes is also possible Approximately 2 times faster than python+TensorFlow with GPU utilization in single-threading |
350 characters/second Cannot be multi-threaded/cannot be simultaneously multi-executed |
|
| Registered pattern dictionary by conventional OCR | Referenced with priority | Referenced with priority | Not available | |
| Language processing | 3-gram dictionary (co-occurrence frequency dictionary) Specialized terminology dictionary |
3-gram dictionary (co-occurrence frequency dictionary) Specialized terminology dictionary AI dictionary |
None | |
| User-registered language dictionary from conventional OCR | Referenced with priority | Referenced with priority | Not available | |
| Supported images | Monochrome binary Grayscale/color can be used by converting to monochrome binary outside the library |
Monochrome binary/grayscale/color | Only grayscale | |