Overview of deep learning OCR
- CNN Deep Learning with a large number of text font images Training using the CNN model with a total of 15,750 different character font images consisting of kanji/hiragana/katakana/symbols and 21,240 different character font images consisting of alphanumeric characters from the smallest standard dictionary.
- Training with the CBOW model of char2vec applied to characters word2vec is a neural network that converts words into multi-dimensional vector representations of attributes.
The total training data size is 200GB. The total number of corresponding character types, including kanji/hiragana/katakana/symbols/alphanumeric characters, has increased to 5,438 character types, with more than 1,000 new character types compared to traditional types.
| Development Process | ||||
|---|---|---|---|---|
| Training | Integrated and converted 74,000 files and 200GB of font patterns + labels into TFRecord format for training with huge data that cannot be processed in memory. TFRecord format is a file format specific to TensorFlow. It enables efficient processing of huge data that cannot fit in memory or training data distributed across thousands of files. The training data converted to TFRecord format is trained with models on TensorFlow/Keras (5.6 million parameters). |
Model CNN MobileNet-I MobileNet-II Hyperparameters Number of layers Number of nodes in each layer Mini-batch size Normalization Loss function Activation functions, etc. Switching while selecting models with fewer parameters and higher accuracy. |
Porting the model to Python/Numpy for execution Porting is relatively simple Output intermediate results in detail |
GPU required SSD required 64-bit operation Not compatible with multi-threading |
| Inference | Porting the model to C++ for execution Porting is relatively difficult Output intermediate results in detail and debug/adjust to make it behave the same as the output in Python/Numpy). |
Further tuning Memory optimization Speed optimization Support for parallel processing using multi-threading |
Integrate deep learning OCR that can be called from a conventional OCR library | GPU not required SSD not required 32-bit/64-bit operation Multi-threading possible |
The inference part was ported from Python to C++ by referring to the Python code.
The training data is vast, amounting to 200GB, and it is naturally impossible to load it all into memory. The training data is converted to a file format called TFRecord by TensorFlow, allowing partial loading of the 200GB data into memory and applying shuffle/mini-batch processing repeatedly in parallel during training.
In addition, GPU is essential for training (which speeds up the training by 10 times). As random access to the 200GB file (in TFRecord format) is required for the training data, it is also necessary to place the data on an SSD.
Using SSD, the data reading speed is more than 40 times faster compared to HDD.
If training is performed without a GPU, for example, using a USB 2.0 connected HDD, it would be extremely disastrous, making it difficult to switch models or tune hyperparameters.
In Keras, models such as CNN/MobileNet I/MobileNet II were tried, and the optimal combination of hyperparameters such as the number of layers/nodes/activation functions/loss functions was researched.
|
MobileNet is a model intended for execution on mobile devices and embedded applications where GPUs and memory resources cannot be expected. In return for reducing memory load and computation, it sacrifices a certain degree of accuracy. This time, MobileNet I and II were tried. The AI inference used in language processing is the entrance part that forms the basics of natural language AI processing. Even in the field of natural language processing, there are lightweight models that consume less memory. Various models have been proposed, such as Mobile BERT for BERT and Mobile ViT using Transformer for image recognition, which sacrifice accuracy to execute on low memory/low-powered machines. However, some models are lightweight to the point where they do not reach practical levels in terms of accuracy. |
Porting to C++ allows for difficult operations in Python such as 32-bit operation and multi-threading. Of course, there are libraries that operate faster in 64-bit environments.
The speed for single-threaded recognition without GPU is about 100-200 characters per second.
By achieving hybrid operation with a high-speed conventional engine, it is possible to achieve 650 characters per second in single-threaded mode. In hybrid operation, it becomes even faster for high-quality document images.
However, with multi-threading enabled and parallel processing utilizing the CPU's multi-core, it becomes possible to achieve speeds of over 1200-7000 characters per second (depending on the number of cores), far surpassing the utilization of GPU.
word2vec, which converts words into multi-dimensional vectors, forms the basis of large language models such as seq2seq used in machine translation and summarization, as well as transformer/BERT/GTP used in robot conversations and paper/case analysis.
In word2vec, words are processed as units, while the char2vec used in this case (existence of an official name "char2vec" is unknown) processes characters as units.
In particular, Japanese kanji characters have many semantic elements that are different from English alphabets. Char2vec is also expected to be somewhat effective.
I did not use the function of word2vec, which is a popular use of calculating distributed representations of words (characters) and finding similarity.
I only used the function of inferring the center character from the surrounding characters.
Furthermore, in terms of experimental accuracy, there is not much difference between the inference by the neural network of char2vec and the statistical inference based on n-gram. Therefore, instead of switching from the conventional n-gram-based language processing to the inference by char2vec, we perform a dual inference of n-gram and char2vec to create a new OCR library language processing.
| Language Processing in Conventional OCR and Deep Learning OCR | |
|---|---|
| Conventional OCR | 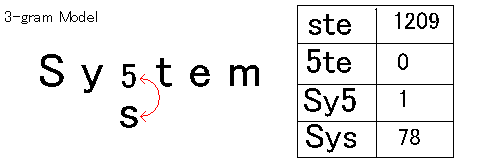 |
| In the 3-gram model, all the frequencies of continuous three characters in the Japanese corpus are counted and stored in a database. In the example above, "System" should be the correct answer, but it is misrecognized as "Sy5tem". The second candidate for the third character contains "s". The frequency of "ste" is higher than the frequency of "5te" (1209 vs 0), and the frequency of "Sys" is higher than the frequency of "Sy5" (78 vs 1). By obtaining this information from the database, the character "5" in the first candidate can be moved down and the character "s" in the second candidate can be adopted. | |
| Deep Learning OCR | 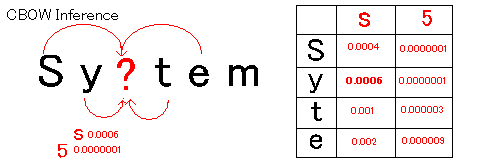 |
| word2vec has a CBOW model that predicts the center character from the surrounding characters and a skip-gram model that predicts the surrounding characters from the center character. This time, we are using the CBOW model that predicts from the previous and next two characters. Looking only at the relationship with the previous character "y", the probability of it being "5" (0.0000001) is lower than the probability of it being "s" (0.006). Therefore, by swapping the candidates, it is possible to change the correct answer to "System". | |